We present Readout Guidance, a method for controlling text-to-image diffusion models with learned signals. Readout Guidance uses readout heads, lightweight networks trained to extract signals from the features of a pre-trained, frozen diffusion model at every timestep. These readouts can encode single-image properties, such as pose, depth, and edges; or higher-order properties that relate multiple images, such as correspondence and appearance similarity. Furthermore, by comparing the readout estimates to a user-defined target, and back-propagating the gradient through the readout head, these estimates can be used to guide the sampling process. Compared to prior methods for conditional generation, Readout Guidance requires significantly fewer added parameters and training samples, and offers a convenient and simple recipe for reproducing different forms of conditional control under a single framework, with a single architecture and sampling procedure. We showcase these benefits in the applications of drag-based manipulation, identity-consistent generation, and spatially aligned control.
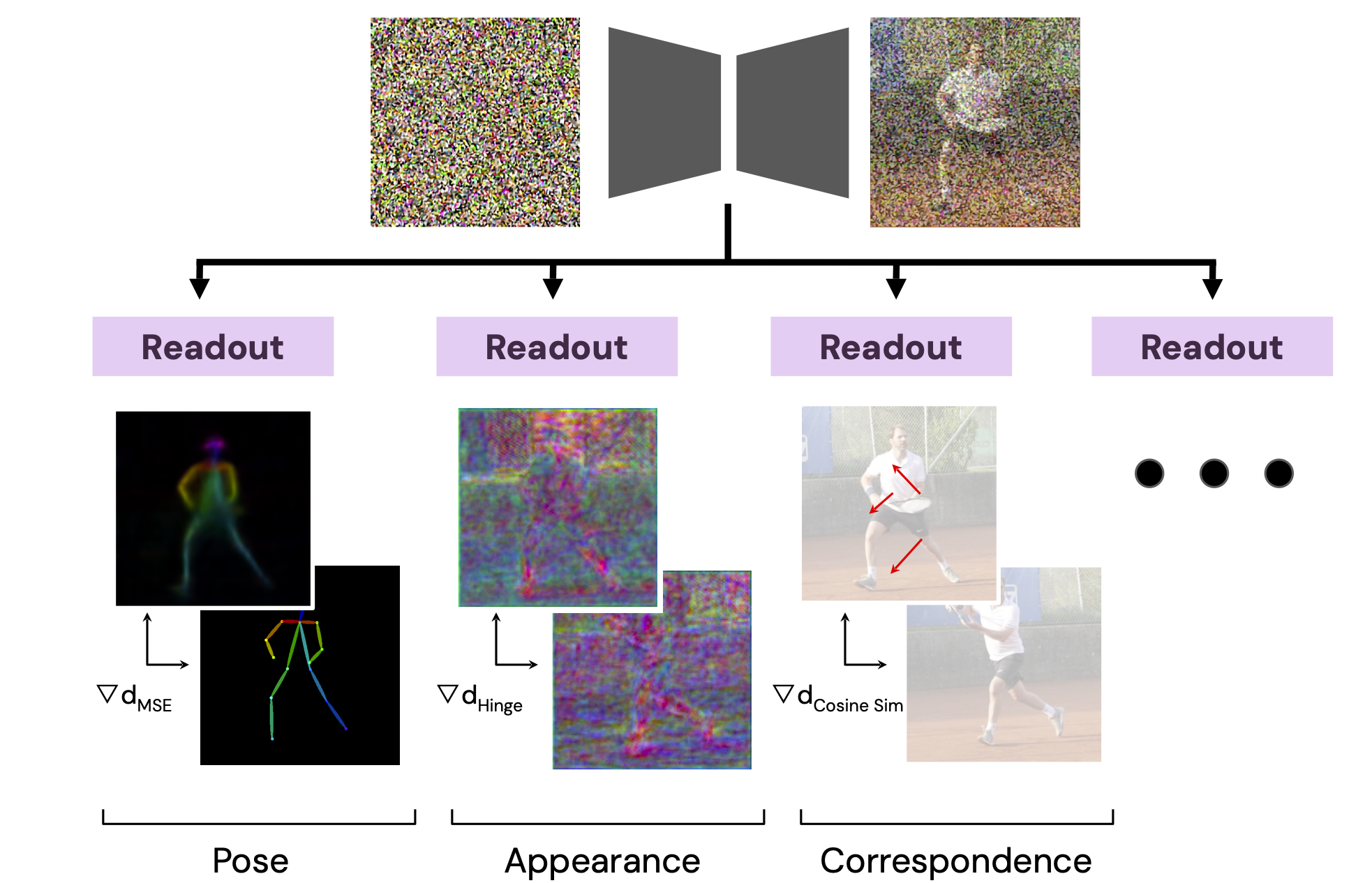
These readouts can also be used for controlled image generation---by guiding the readout towards some desired value. Readouts for single-image concepts, such as pose and depth, enable spatially aligned control. Readouts for relative concepts between two images, such as appearance similarity and correspondence, enable cross-image controls, such as drag-based manipulation, identity-consistent generation, or image variations.






@inproceedings{luo2024readoutguidance,
title={Readout Guidance: Learning Control from Diffusion Features},
author={Grace Luo and Trevor Darrell and Oliver Wang and Dan B Goldman and Aleksander Holynski},
booktitle={CVPR},
year={2024}
}
